Sem
@sem
@lemmy.ml@sem
@lemmy.mlhttps://geekpython.in/copy-on-write-in-pandas
Pandas supports Copy-on-Write, an optimization technique that helps improve memory use, particularly when working with large datasets.

https://www.ftc.gov/news-events/news/press-releases/2024/07/ftc-issues-orders-eight-companies-seeking-information-surveillance-pricing
The Federal Trade Commission issued orders to eight companies offering surveillance pricing products and services that incorporate data about consumers’ characteristics and behavior.

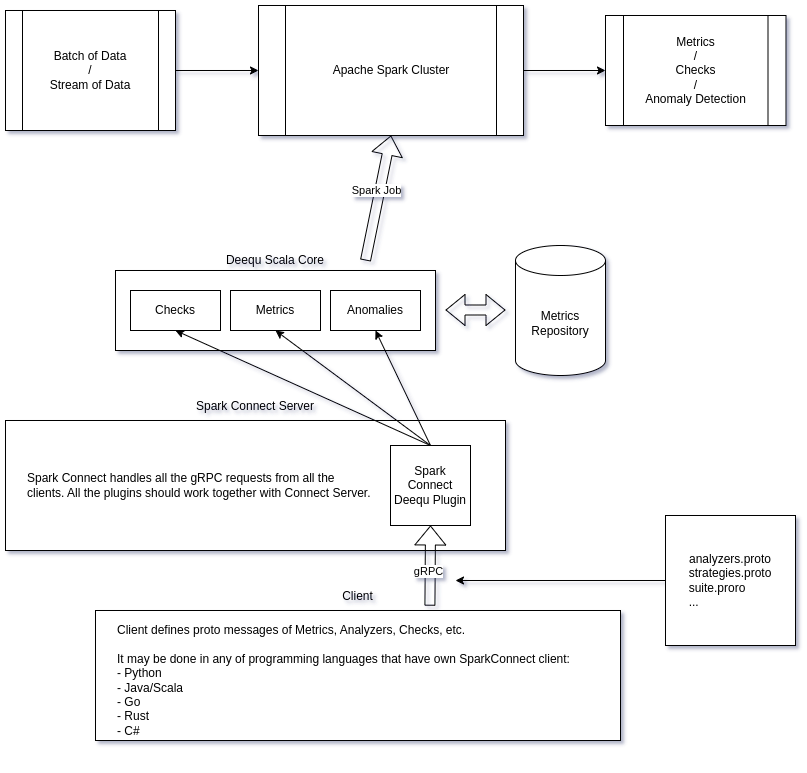
https://semyonsinchenko.github.io/ssinchenko/post/porting_deequ_to_sparkconnect/
Summary This blog post is a detailed story about how I ported a popular data quality framework, AWS Deequ, to Spark-Connect. Deequ is a very cool, reliable and scalable framework that allows to compute a lot of metrics, checks and anomaly detection suites on the data using Apache Spark cluster. But the Deequ core is a Scala library that uses a lot of low-level Apache Spark APIs for better performance, so it cannot be run directly on any of Spark-Connect environment.
I have my personal blog, made with Hugo and hosted on GitHub pages. Initially I did not turn on any kind of web tracking / web analytics, because I do not like tracking at all. But I want to make my blog better and to achieve it, I need a feedback loop about traffic. For example, what are the most popular publications, or how many people view my blog from mobile devices, etc.
So, my question is, what is the most appropriate (ot the less evil) way to track a web traffic?
An answer "there is no good way to do it without breaking user's privacy" is acceptable too, I did not decide yet turning on the analytics. Instead I'm interested in an opinion of the community.
Thanks in advance!
https://www.science.org/doi/10.1126/sciadv.adl0335
https://github.com/apache/arrow-datafusion-comet/pull/1
This is the initial PR for Comet. Related mailing list discussion: https://lists.apache.org/thread/0q1rb11jtpopc7vt1ffdzro0omblsh0s