Efficiently Manage Memory Usage in Pandas with Large Datasets
Efficiently Manage Memory Usage in Pandas with Large Datasets
https://geekpython.in/copy-on-write-in-pandas
Pandas supports Copy-on-Write, an optimization technique that helps improve memory use, particularly when working with large datasets.

Shift Left
Just a moment...
https://medium.com/@nydas/4-key-benefits-of-shift-left-ff0e4bb74a3f?source=friends_link&sk=0941f5164f5115f6fe88191f0b1b9683
Dremio is offering free pdf copies of "Apache Iceberg: The Definitive Guide: Data Lakehouse Functionality, Performance and Scalability on the Data Lake"
Dremio Unified Analytics Platform for a Self-Service Lakehouse
https://hello.dremio.com/wp-apache-iceberg-the-definitive-guide-reg.html
The Dremio Unified Lakehouse Platform for self-service analytics and AI, powered by a performant SQL Query Engine and Apache-native Lakehouse Management
Postgres vs. Pinecone | Lantern Blog | Narek Galstyan | July 18, 2024
Postgres vs. Pinecone | Lantern Blog
https://lantern.dev/blog/postgres-vs-pinecone
We respond to Pinecone's recent blog post comparing Postgres and Pinecone. We show that Postgres can outperform Pinecone in the same benchmarks Pinecone covered in their article.

Definite: Comparing Iceberg Query Engines (with Duckdb and Iceberg Full Notebook Example) | Steven Wang | 7/3/2024
Definite: Duckdb and Iceberg
https://www.definite.app/blog/iceberg-query-engine
Definite: Duckdb and Iceberg

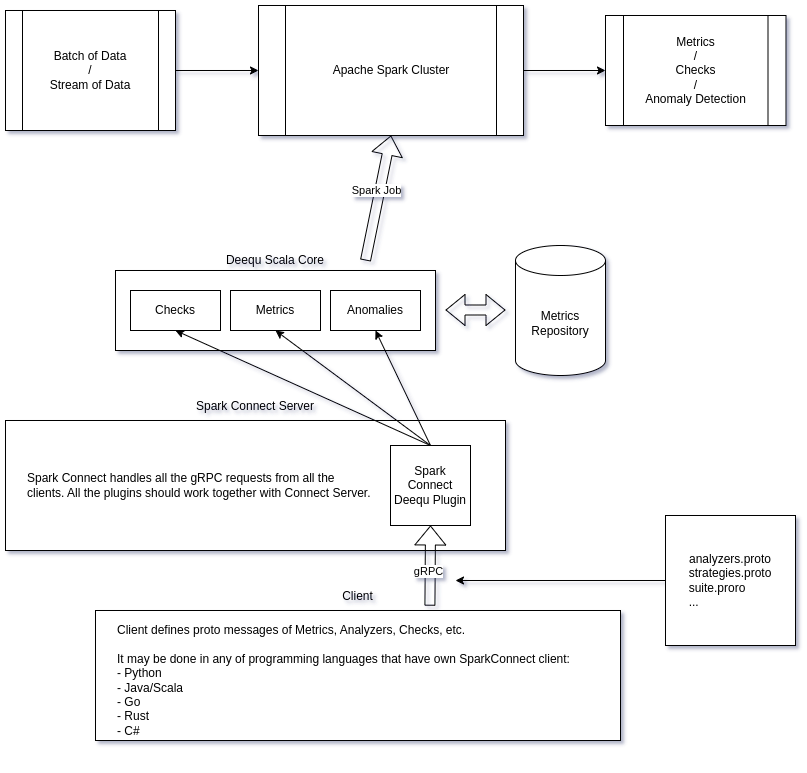
A guide how to adopt an existing Spark scala library for Spark Connect
Spark-Connect: I'm starting to love it!
https://semyonsinchenko.github.io/ssinchenko/post/porting_deequ_to_sparkconnect/
Summary This blog post is a detailed story about how I ported a popular data quality framework, AWS Deequ, to Spark-Connect. Deequ is a very cool, reliable and scalable framework that allows to compute a lot of metrics, checks and anomaly detection suites on the data using Apache Spark cluster. But the Deequ core is a Scala library that uses a lot of low-level Apache Spark APIs for better performance, so it cannot be run directly on any of Spark-Connect environment.
Why Use Data Build Tools (dbt)
Just a moment...
https://medium.com/@nydas/the-power-of-data-build-tool-dbt-6b26dfab5bac?source=friends_link&sk=4ad30d3dc20fe25a2d5d474372f6c71a
7 best open-source chart libraries for developers
7 Best Chart Libraries For Developers In 2024 🤯
https://dev.to/latitude/7-best-chart-libraries-for-developers-in-2024-25he
Many applications use charts or graphs for data visualization, which can be implemented using...

Building a real-time data pipeline - Technical article and GitHub repo
Just a moment...
https://medium.com/@nydas/building-a-real-time-data-pipeline-5eff6c6d8a3c?source=friends_link&sk=8d8792af4527b0d6f91f430ebdc40fc7
Diagrams as Code
Just a moment...
https://medium.com/@nydas/diagrams-as-code-streamlining-erd-creation-for-data-engineers-f1e305cf69ef