Is there a way to scale the Lightness in OKLab/OKLCH color space, so it becomes identical to lightness in CIELAB? I want use OKLab to create tonal palettes, that requires a change in lightness scale
Is there a way to scale the Lightness in OKLab/OKLCH color space, so it becomes identical to lightness in CIELAB? I want use OKLab to create tonal palettes, that requires a change in lightness scale since OKLab's lightness scale perfoms poorly in this regard.
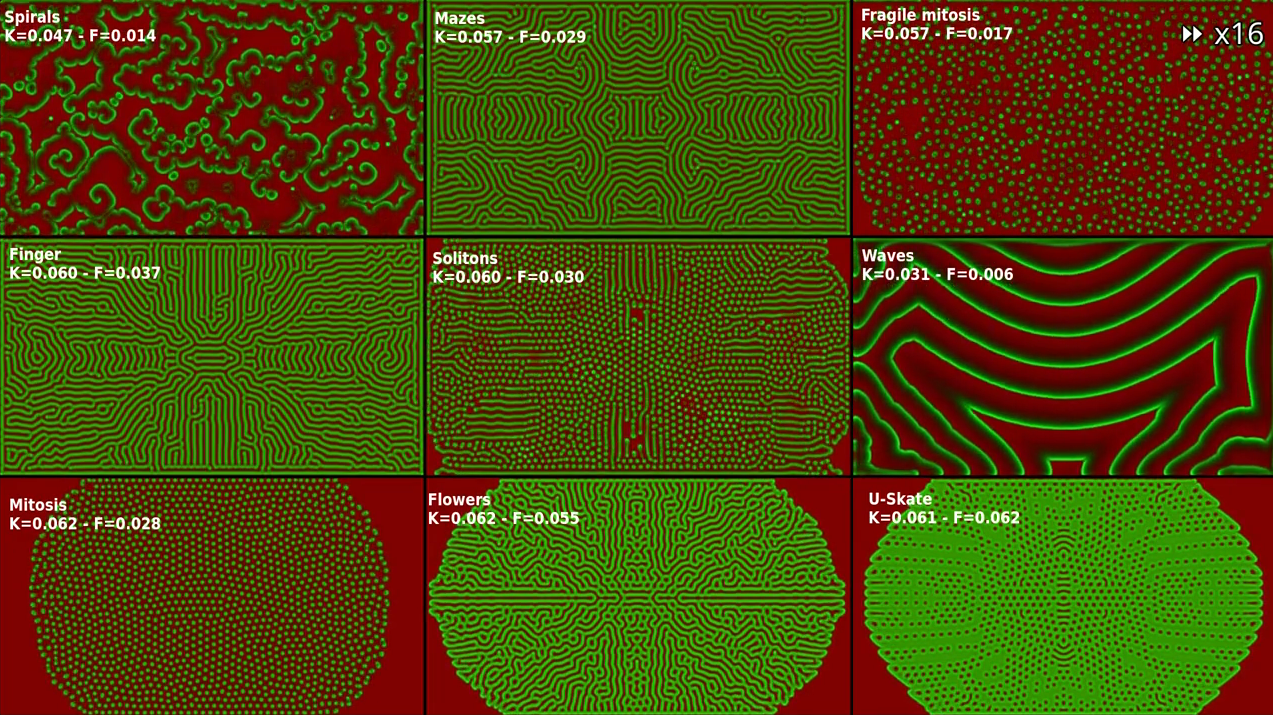
Mitosis in the Gray-Scott model : an introduction to writing shader-based chemical simulations
Mitosis in the Gray-Scott model : an introduction to writing shader-based chemical simulations
https://pierre-couy.dev/simulations/2024/09/gray-scott-shader.html
Use the parallel processing power of your GPU to simulate a simple chemical system that exhibits emergent behaviors
Vector Graphics in Qt 6.8
Vector Graphics in Qt 6.8
https://www.qt.io/blog/vector-graphics-in-qt-6.8
An overview of the existing vector graphics solution in Qt 6.7 and prior, as well as the upcoming additions in Qt 6.8

Dependabot alternatives for non-github hosts?
I'm really bad at keeping my dependencies up-to-date manually, so dependabot was great for me. I don't use github anymore though, and I haven't really been able to find a good alternative.
I found Snyk, which seems to do that, but they only allow logging in with 3rd party providers which I'm not a big fan of.
Edit: seems like Snyk also only supports a few git hosts, and Codeberg isn't one of them.
Are there better alternatives to null-terminated strings?
GitHub - free-news-api/news-api: Top Free News API Comparison
GitHub - free-news-api/news-api: Top Free News API Comparison
https://github.com/free-news-api/news-api
Top Free News API Comparison. Contribute to free-news-api/news-api development by creating an account on GitHub.
Make puppeteer wait for a page to fully load
Taking accurate screenshots with Puppeteer has been a real pain, especially with pages that don’t fully load when the standard waitUntil: load fires. A real pain. Some sites, particularly SPAs built with Angular, React, or Vue, end up half-loaded, leaving me with screenshots where parts of the page are just blank. Peachy, just peachy.
I've had the same issue with waitUntil: domcontentloaded, but that one was kind of expected. The problem is that the page load event fires too early, and for pages relying on JavaScript to load images or other resources, this means the screenshot captures a half-baked page. Useless, obviously.
After some digging accompanied by a certain type of language (the beep type), I did find a few workarounds. For example, you can use Puppeteer to wait for specific DOM elements to appear or disappear. Another approach is to wait for the network to be idle for a certain time. But what really helped was finding a custom function that waits for the DOM updates to settle (source). It’s the closest to a solution for getting fully loaded screenshots across different types of websites, at least from what I was able to find. Hope it will help anyone who struggles with this issue.
LLMs as interactive rubber ducks (or Q&A trainers)
I initially wrote this as a response to this joke post, but I think it deserves a separate post.
As a software engineer, I am deeply familiar with the concept of rubber duck debugging. It's fascinating how "just" (re-)phrasing a problem can open up path to a solution or shed light on own misconceptions or confusions. (As and aside, I find that among other things that have similar effect is writing commit messages, and also re-reading own code under a different "lighting": for instance, after I finish a branch and push it to GitLab, I will sometimes immediately go and review the code (or just the diff) in GitLab (as opposed to my terminal or editor) and sometimes realize new things.)
But another thing I've been realizing for some time is that these "a-ha" moments are always mixed feelings. Sure it's great I've been able to find the solution but it also feels like bit of a downer. I suspect that while crafting the question, I've been subconsciously also looking forward for the social interaction coming from asking that question. Suddenly belonging to a group of engineers having a crack at the problem.
The thing is: I don't get that with ChatGPT. I don't get that since there's was not going to be any social interaction to begin with.
With ChatGPT, I can do the rubber duck debugging thing without the sad part.
If no rubber duck debugging happens, and ChatGPT answers my question, then that's obvious, can move on.
If no rubber duck debugging happens, and ChatGPT fails to answer my question, then by the time at least I got some clarity about the problem which I can re-use to phrase my question with an actual community of peers, be it IRC channel, a Discord server or our team Slack channel.
So I'm wondering, do other people tend to use LLMs as these sort of interactive rubber ducks?
And as a bit of a stretch of this idea---could LLM be thought of as a tool to practice asking question, prior to actually asking real people?
PS: I should mention that I'm also not a native English speaker (which I guess is probably obvious by now by my writing) so part of my "learning asking question" is also learning it specifically in English.
Are SW design patterns guilty until proven otherwise?
I started writing this as an answer to someone on some discord, but it would not fit the channel topic, but I'd still love to see people's views on this.
So I'll quote the comment but just as a primer:
The safest pattern to use is to not use any pattern at all and write the most straight forward code. Apply patterns only when the simplest code is actually causing real problems.
First and foremost: Many paths to hell are paved with design patterns applied willy-nilly. (A funny aside: OO community seems to be more active and organized in describing them (and often not warning strongly enough about dangers of inheritance, the true lord of the pattern rings), which leads to the lower-level, simpler patterns being underrepresented.)
But, the other extreme is not without issues, by far.
I've seen too many FastAPI endpoints talking to db like there's no tomorrow. That is definitely "straight forward" approach but the first problem is already there: it's pretty much untestable, and soon enough everyone is coupling to random DB columns (and making random assumptions about their content, usually based on "well let's see who writes what there" analysis) which makes it hard to change without playing a whack-a-bug.
And what? Our initial DB design was not future proof? Tough luck changing it now. So new endpoints will actually be trying to make up for the obsolete schema, using pandas everywhere to do what SQL or some storage layer (perhaps with some unit-of-work pattern) should be doing -- and further cementing in the obsolete design. Eventually it's close to impossible to know who writes/expects what, so now everyone better be defensive, adding even more cruft (and space for bugs).
My point is, I guess, that by the time when there are identifiable "real problems" to be solved by pattern, it's far too late.
Look, in general, postponing a decision to have more information can be a great strategy. But that depends on the quality of information you get by postponing. If that extra information is going to be just new features you added in the meantime, that is going to be heavily biased by the amount of defensive / making-up-for-bad-db junk that you forced yourself to keep adding. It's not necessarily going to be easier to see the right pattern.
So the tricky part is, which patterns are actually strong enough yet not necessarily obtrusive, so that you can start applying them early on? That's a million dollar question.
I don't think "straight forward" gets you towards answering that question. (Well, to be fair, I'm sure people have made $1M with "straight forward code", so that's that, but is that a good bet?)
(By the way, real world actually has a nice pattern specifically for getting out of that hole, and it's called "your competitor moving faster & being cheaper than you" so in a healthy market the problem should solve itself eventually...)
So what are your ideas? Do you have design patterns / disciplines that you tend to apply generally, with new projects?
I'm not looking for actual patterns (although it's fine to suggest your favorites, or link to resources), I'm mainly interested in what do people think about patterns in general, and how to apply them during the lifetime of the project.
2024 Stack Overflow Developer Survey
2024 Stack Overflow Developer Survey
https://survey.stackoverflow.co/2024/
In May 2024, over 65,000 developers responded to our annual survey about coding, the technologies and tools they use and want to learn, AI, and developer experience at work. Check out the results and see what's new for Stack Overflow users.