Will adding K8S CPU limit reduce service performance?
Will adding K8S CPU limit reduce service performance?
https://www.sobyte.net/post/2022-04/k8s-cpu-limit/
Explore whether adding the K8S CPU limit will degrade service performance.
Exploring How Cache Memory Really Works
Exploring How Cache Memory Really Works
https://pikuma.com/blog/understanding-computer-cache
Even though we often hear terms like L1, L2, cache block size, etc., most programmers have a limited understanding of what cache really is. This is a beginner-friendly primer on how cache works.

Measure Your Maven Build · Maarten on IT
Measure Your Maven Build · Maarten on IT
https://maarten.mulders.it/2024/03/measure-your-maven-build/
This blog introduces three mechanisms to investigate the execution time of a Maven build. Having a reliable way to measure build execution time can help identify bottlenecks. This in turn helps making effective improvements, thereby contributing to higher developer productivity. Find out how to effectively identify performance bottlenecks in your Maven builds.

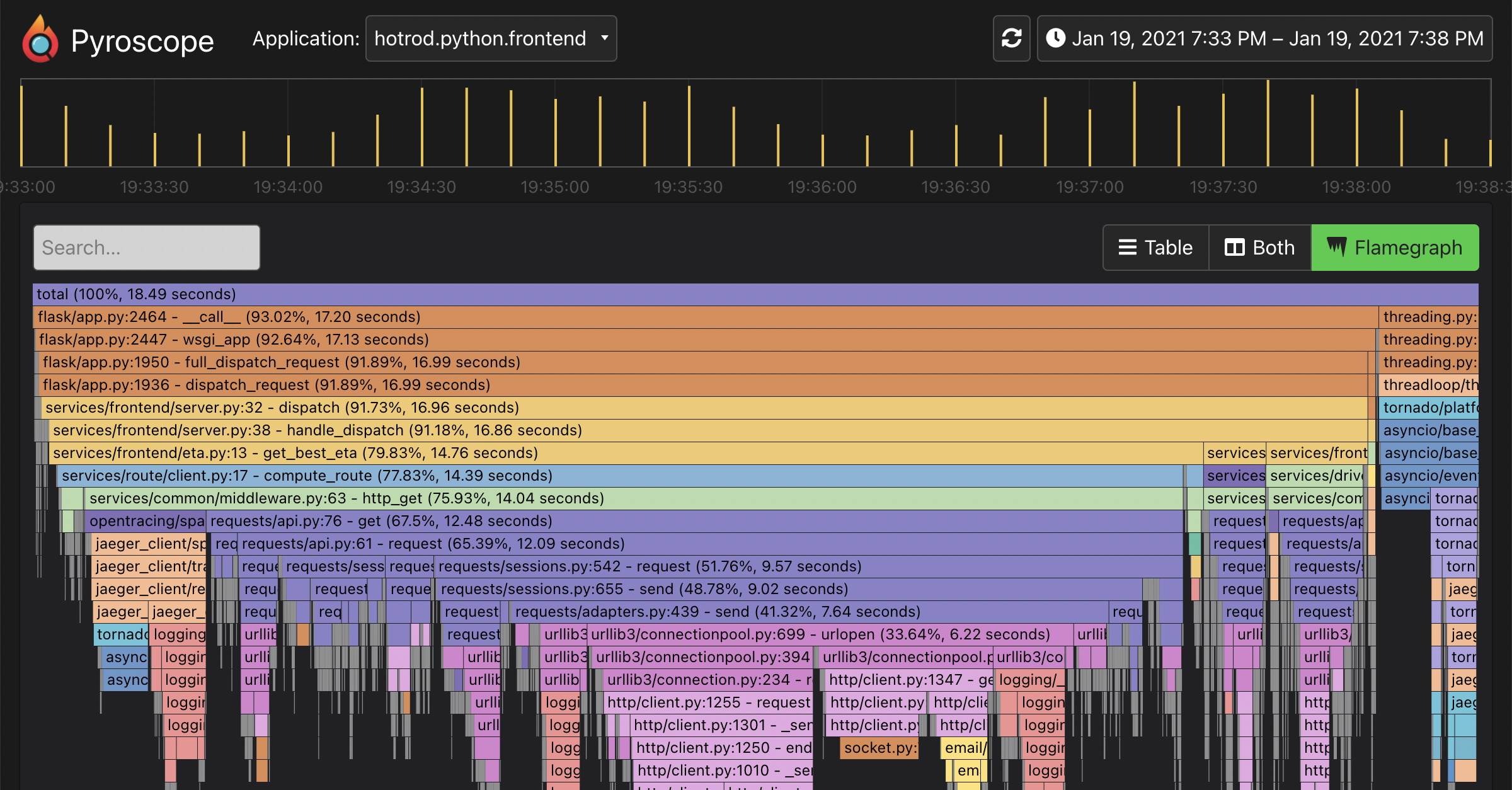
AI-Powered Flamegraph Interpreter in Grafana Pyroscope | Open Source Continuous Profiling Platform
AI-Powered Flamegraph Interpreter in Grafana Pyroscope | Open Source Continuous Profiling Platform
https://pyroscope.io/blog/ai-powered-flamegraph-interpreter/
Explore how our AI-powered tool is revolutionizing flamegraph interpretation
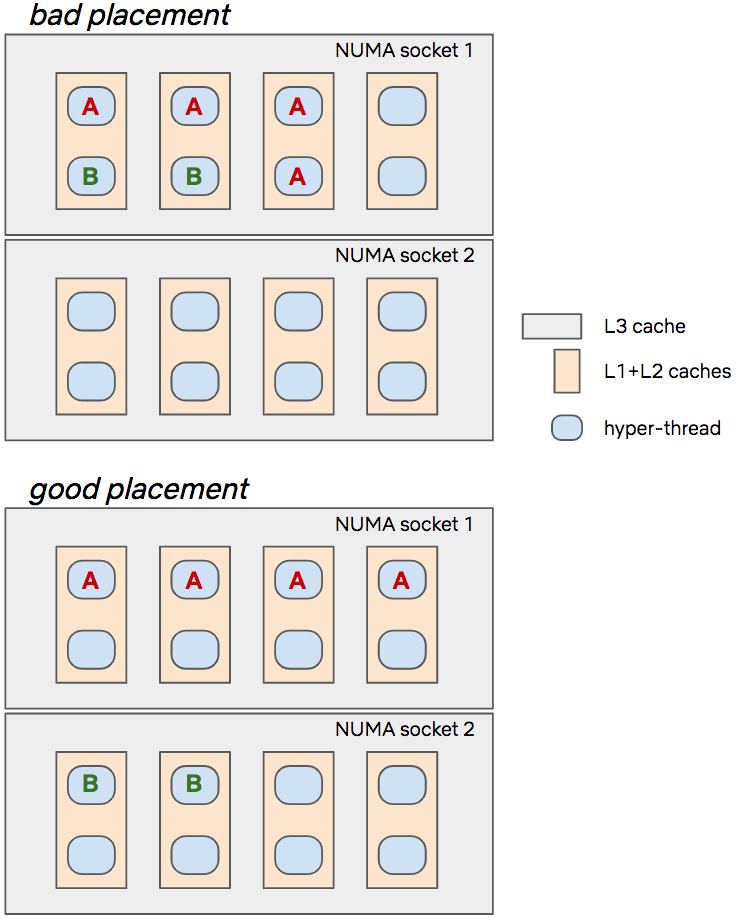
Using perf to profile Java applications
Using perf to profile Java applications | BellSoft Java
https://bell-sw.com/announcements/2022/04/07/how-to-use-perf-to-monitor-java-performance/
Find out how to use perf, a built-in Linux profiler, to analyze the performance of Java applications.
What would happen to low latency trading if exchanges moved to the cloud?
https://blog.abctaylor.com/what-would-happen-to-low-latency-trading-if-exchanges-moved-to-the-cloud/
No Restarts, No Disruptions: Seamless Pod Resource updates with In-Place Resizing
Just a moment...
https://engineering.doit.com/no-restarts-no-disruptions-seamless-pod-resource-updates-with-in-place-resizing-f3cf41654216

Predictive CPU isolation of containers at Netflix
Just a moment...
https://netflixtechblog.com/predictive-cpu-isolation-of-containers-at-netflix-91f014d856c7
LLaMA Now Goes Faster on CPUs
LLaMA Now Goes Faster on CPUs
https://justine.lol/matmul/
I wrote 84 new matmul kernels to improve llamafile CPU performance.

Bump Allocation: Up or Down?
Bump Allocation: Up or Down?
https://coredumped.dev/2024/03/25/bump-allocation-up-or-down/
Back in 2019, Nick Fitzgerald published always bump downwards, an article making the case that for bump allocators, bumping “down” (towards lower addresses) is better than bumping up. The biggest reasons for this are bumping up requires 3 branches vs 2 for bumping down and rounding down requires fewer instructions than rounding up. This became the method used for the popular bumpalo crate. In this post, I want to go back and revisit that analysis.