
No Stupid Questions (Developer Edition)
!no_stupid_questions
@programming.dev!no_stupid_questions
@programming.devTo my understanding:
Many terminals are capable of displaying multiple fonts at the same time, say latin unicode characters in font foo and japanese unicode characters in font baz. In urxvt at least, it is also possible to have one font in a certain size and the next font in another size. However, no font can have a size bigger than the base size, the size of a terminal cell.
Why is it not possible to have multiple terminal cell sizes? For exampleso one line has terminal size 8 and the next line has terminal size 12.
The wikipedia articles are terribly written (for math loves or people who just need to refresh their knowledge).
What is a "sum" of types? What is a product of types? Is it possible to Cat x Dog or Cat + Dog? What does that even mean?
So I want to build blender fork but it fails to build on Visual Studio 2022. There is already a patch and a open PR that fixes the issue.
I have already git cloned the repository and I would want to only get the patch into my local repository. So I can build from that.
Limitation of using drag and drop Images in readme.md?
One I am aware of is the size limit that no image size should be >10 MB. Are there any other limitations when using this (for example: retention period, storage capacity, etc)? I want to link those images outside Github.
I am aware of uploading images to the repository and linking by
[image](./path/to/image/image.png)
You see this with some apps (I think ReVanced is a popular example?) and games occasionally, and I've never been clear on how they do it.
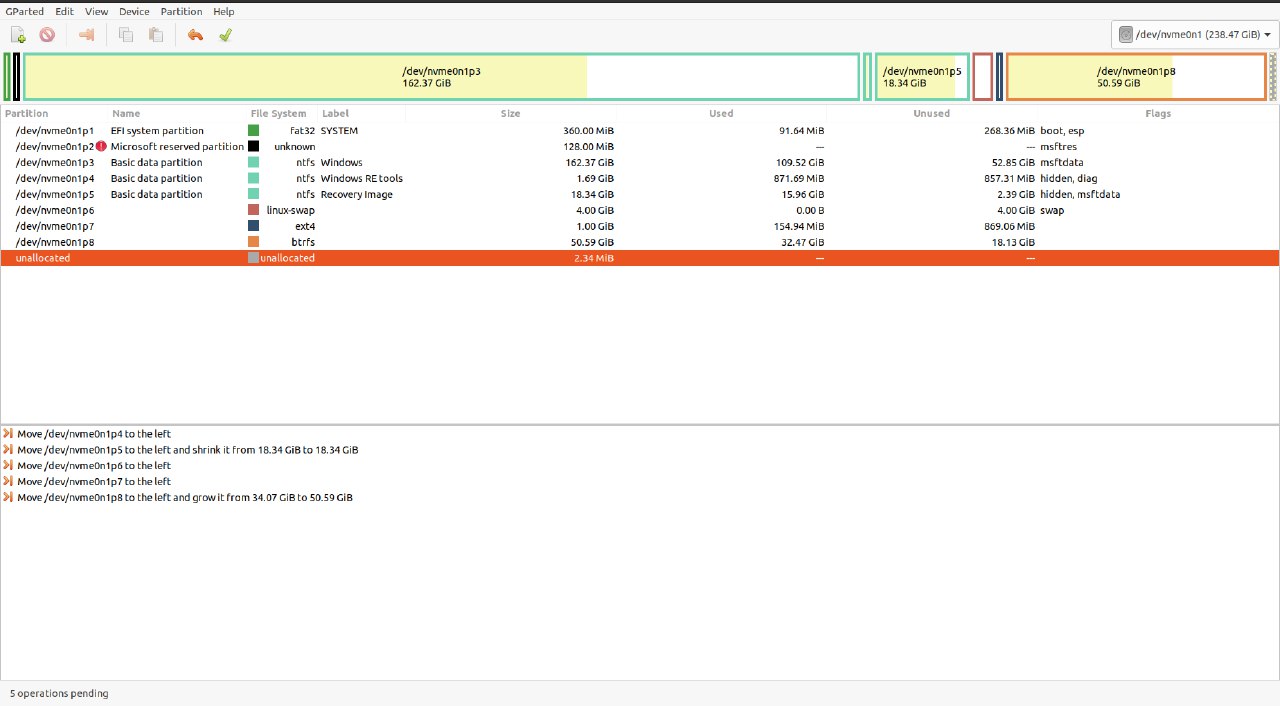
Hello. I have Windows - Ubuntu dual boot and I'm trying to move space from Windows to Ubuntu. I've already freed space from the Windows side
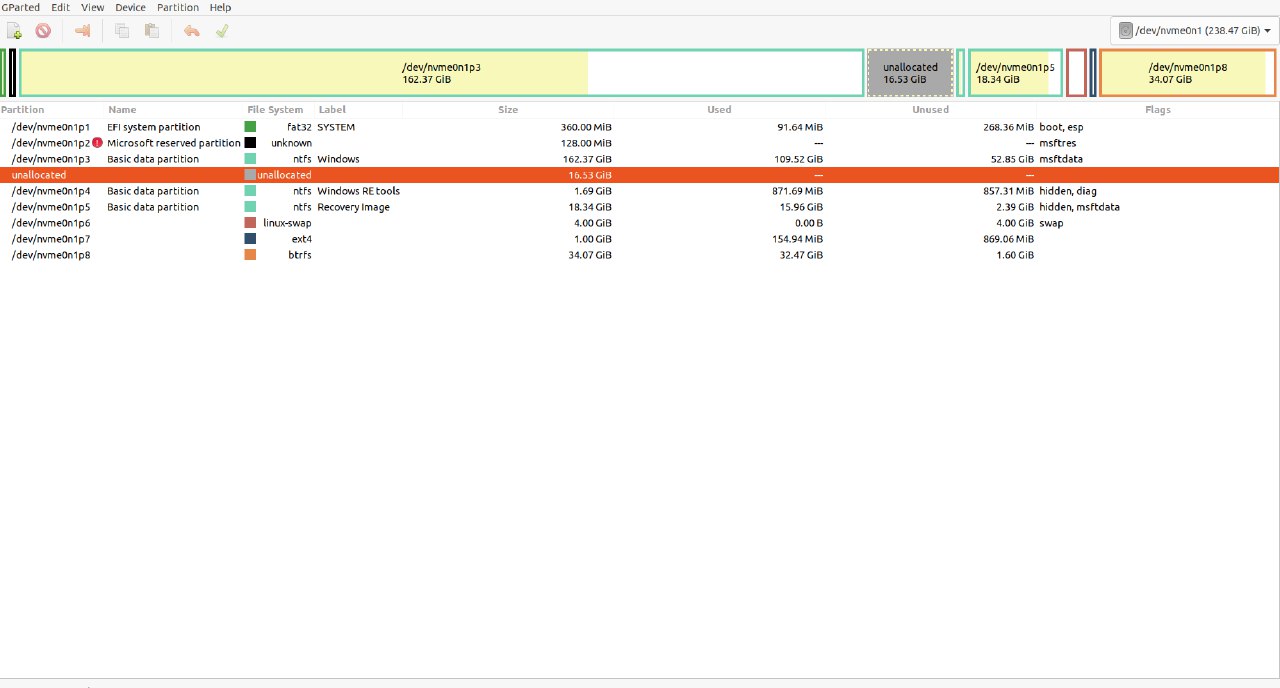
I'm pretty sure that I've read online that it can be dangerous to move the unallocated partition, because next boot to windows can corrupt my Ubuntu system. Is it true? Also, when I'm trying to move the unallocated partition, there's no option to "move/resize", so I swap them with the next following partition one by one. Is it the right way to do it?
So I'm a baby dev, still in Uni and they don't allow internships in 4th year due to some issues with it so not even that exp wise.
I don't know enough, and I'm trying to learn but there's so much! My Uni degree doesn't cover security at all. Which is shit, bc I think I want to work in that? Mostly I'm just spooked and want to understand everything I can 'cause I love the internet and want to feel safer wandering about it.
I'm scared of clicking on links. Even ones here, like there was a post about a book list earlier and I was just there like "Cmoon.... someone please have posted the lissssst."
Would anyone be willing to share what they do for their own security? Especially if it's ridiculously over the top. Included reasonings and details would be adored!
Also, if anyone has any books or references that might be good for learning sec from a programmatic view rather than a IT view I'd really love that! Anything at all.
Regardless, hope anyone reading this has an absolutely wonderful day and best of luck with everything you're up to!
Can't locally download 41 GB loaded image which is provided to replicate GitHub action locally but don't want to commit and check every time too, is there any third option?
I think from what I've read that this is the case, but I've read some other info that's made it less clear to me.
On the second part of the question regarding container engines, I'm pretty sure that may also be correct, and it kinda makes me wonder a little about risks of engine lock-in, but that may be a little out of scope.
cross-posted from: https://programming.dev/post/6513133
Short explanation of the title: imagine you have a legacy mudball codebase in which most service methods are usually querying the database (through EF), modifying some data and then saving it in at the end of the method.
This code is hard to debug, impossible to write unit tests for and generally performs badly because developers often make unoptimized or redundant db hits in these methods.
What I've started doing is to often make all the data loads before the method call, put it in a generic cache class (it's mostly dictionaries internally), and then use that as a parameter or a member variable for the method - everything in the method then gets or saves the data to that cache, its not allowed to do db hits on its own anymore.
I can now also unit test this code as long as I manually fill the cache with test data beforehand. I just need to make sure that i actually preload everything in advance (which is not always possible) so I have it ready when I need it in the method.
Is this good practice? Is there a name for it, whether it's a pattern or an anti-pattern? I'm tempted to say that this is just a janky repository pattern but it seems different since it's more about how you time and cache data loads for that method individually, rather than overall implementation of data access across the app.
In either case, I'd like to learn either how to improve it, or how to replace it.